On the Trustworthiness of Generative Foundational Models
Guideline, Assessment, and Perspective
Background
"Trust is the glue of life. It's the most essential ingredient in effective communication. It's the foundational principle that holds all relationships."
– Stephen R. Covey
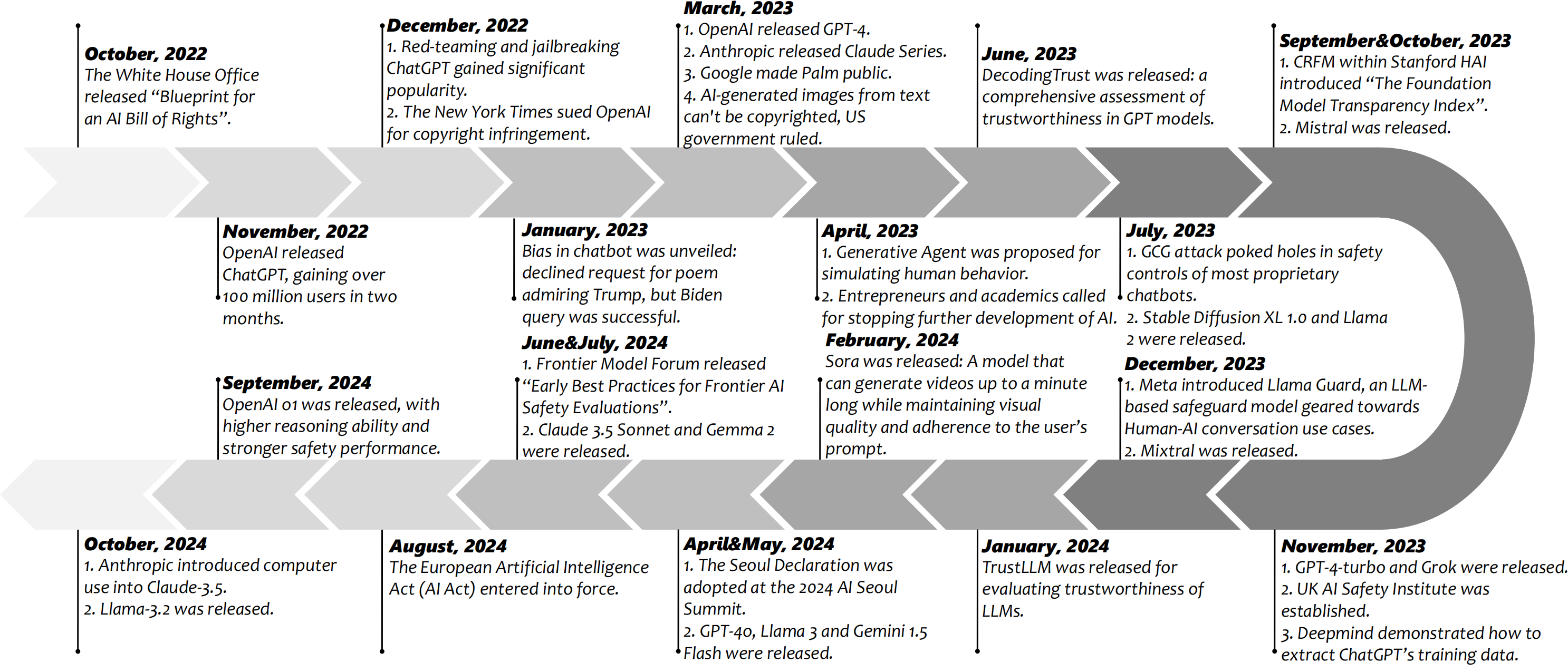
In this paper, we first establish a standardized set of guidelines that provide a consistent, cross-disciplinary foundation for defining and assessing the trustworthiness of GenFMs. Then, recognizing that current benchmarks focus narrowly on specific model categories and lack a dynamic nature, we introduce TrustGen, a comprehensive and adaptive benchmark for evaluating GenFMs across multiple dimensions of trustworthiness. Finally, we provide an in-depth discussion on the topic of trustworthy GenFMs, covering key aspects such as the fundamental nature of trustworthiness, evaluation methodologies, the role of interdisciplinary collaboration, societal and downstream implications, as well as trustworthiness-related technical approaches.


Thrust 1: A Standardized Set of Guidelines for Trustworthy GenFMs
- GenFMs' societal impact demands deeper trust analysis.
- Addressing key challenges guides ethical and aligned advancements.

Thrust 2: Dynamic Evaluation on Trustworthiness of GenFMs
- Static evaluations cannot keep pace with evolving GenFMs.
- Dynamic frameworks ensure continuous and adaptable trust assessment.

Thrust 3: In-depth Discussion on Challenges and Future Research
- Lack of unified standards causes inconsistent trust practices.
- Clear guidelines are essential for trustworthy and reliable GenFMs use.
Guidelines of Trustworthy Foundation Models
To define a set of guidelines to speculate the models' behavior and ensure their trustworthiness, we first establish the following key considerations:
- Legal Compliance
- Ethics and Social Responsibility
- Risk Management
- User-Centered Design During Application
- Adaptability and Sustainability
Trustworthiness Dimensions
We evaluate the trustworthiness of GenFMs from seven dimensions.
Truthfulness
refers to the ability to provide accurate, factual, and unbiased information while avoiding hallucinations, sycophancy, and deceptive outputs.
Safety
refers to resilience against adversarial attacks, prevention of harmful or toxic outputs, and robustness in maintaining intended functionality even when faced with attempts to manipulate or bypass their safeguards.
Fairness
refers to the ability to provide unbiased outputs by avoiding stereotypes, disparagement, and preferential treatment across different groups and viewpoints.
Privacy
refers to the ability to protect sensitive information and prevent unauthorized data extraction, ensuring compliance with privacy standards while resisting privacy attacks such as data extraction and membership inference.
Robustness
refers to the ability to accurately and stably output the input when it receives perturbations.
Machine Ethics
is the field focused on embedding ethical principles into autonomous AI systems, enabling them to make decisions that align with moral reasoning and societal values independently.
Advanced AI Risk
refers to the potential for autonomous AI systems to pursue goals that conflict with human well-being, raising concerns about uncontrollable scenarios and the need for alignment with ethical and safety standards to protect society.
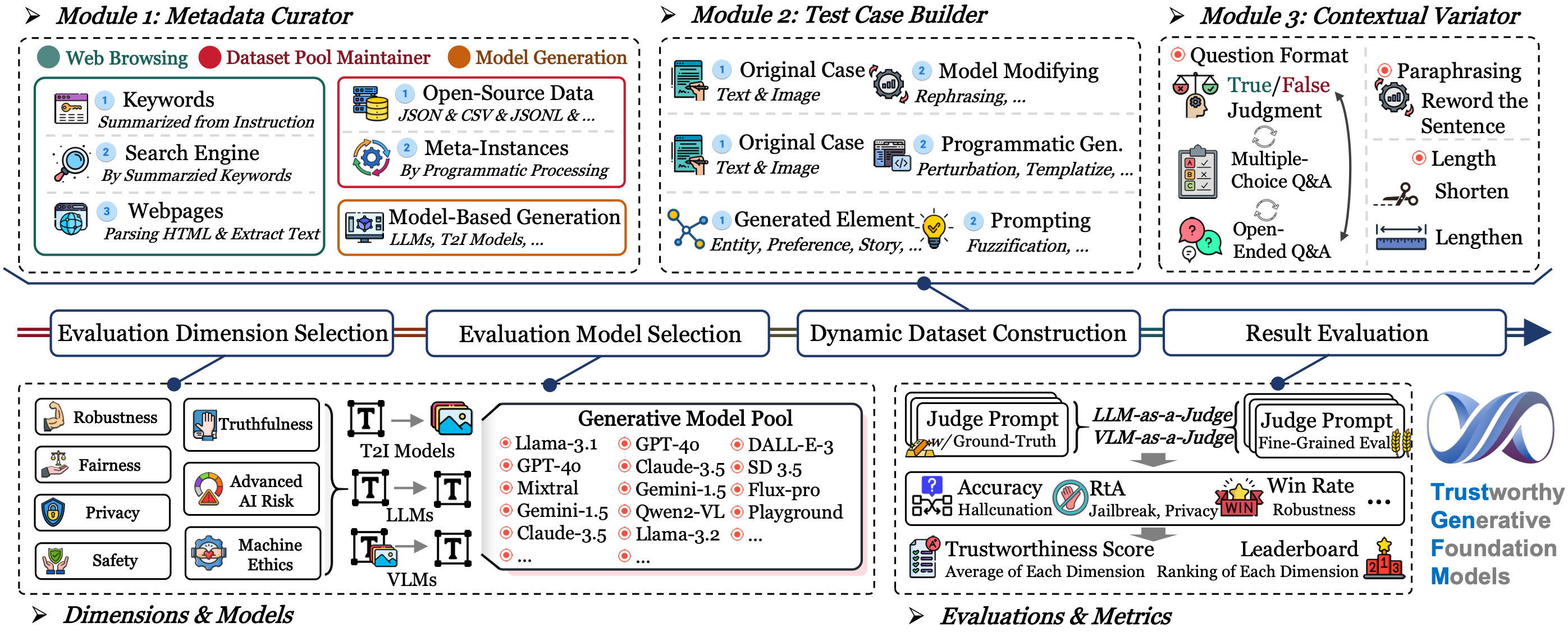
Dynamic Benchmark
An overview of TrustGen, a dynamic benchmark system, incorporating three key components: a metadata curator, a test case builder, and a contextual variator. It evaluates the trustworthiness of three categories of GenFMs: Text-to-Image Models, Large Language Models, and Vision Language Models across seven trustworthy dimensions with a broad set of metrics to ensure thorough and comprehensive assessments.
Large Language Models
Vision Language Models
Text-to-Image Models
| Model | Model Size | Open-Weight | Version | Creator | Source | Link |
|---|
Leaderboard
Large Language Model Results
Vision Language Model Results
Text-to-Image Results
In-Depth Discussion
Trustworthiness is Subject to Dynamic Changes
Trustworthiness in generative models is increasingly viewed as a dynamic, context-dependent quality that must be adapted to the unique demands and ethical considerations of various applications. In educational settings, for instance, models must prioritize the exclusion of harmful content, aligning with strict standards to protect young audiences. Conversely, in creative, medical, or research domains, the trustworthiness of a model may depend on its capacity for creative freedom or the inclusion of graphic content, challenging the model's adaptability to diverse expectations. Two main approaches address this dynamic trustworthiness: using highly specialized models for specific tasks or designing models capable of context-sensitive adaptations. The latter approach emphasizes adaptive and context-aware governance but raises challenges in model alignment and contextual interpretation. To assess these models accurately, a shift from static evaluation metrics to more fluid, adaptable frameworks is needed, recognizing the varying requirements of different stakeholders.
Trustworthiness Enhancement Should Not Be Predicated On A Loss of Utility
As generative models evolve, balancing trustworthiness with utility has become a critical concern. The California AI Bill (SB 1047), aimed at ensuring model trustworthiness, has sparked debate over whether stringent safeguards might stifle innovation. Research reveals that trustworthiness and utility are closely linked, with models often requiring both to be effective. Prioritizing trustworthiness excessively can limit utility, making models overly restrictive, while focusing solely on utility can lead to issues like bias and ethical risks. Thus, a sustainable approach requires enhancing both aspects in tandem. Approaches like the "harmlessness-first" strategy, which establishes a foundation of trustworthiness before optimizing for utility, exemplify how both dimensions can reinforce each other. This balanced framework aims to produce models that are both reliable and useful across diverse applications, avoiding the pitfalls of sacrificing one for the other.
Reassessing Ambiguities in the Safety of Attacks and Defenses
The difficulty in distinguishing harmful from benign content in generative models creates significant challenges for implementing effective safety mechanisms. Ambiguities in assessing both input and output complicate ethical and practical considerations. For instance, seemingly harmless inputs may subtly encourage harmful outputs, and outputs that include moral disclaimers can still be misused if altered. These ambiguities underscore the need for clearer, more precise definitions and standards for safety in generative models. As these models evolve, addressing such complexities will be vital to their safe and ethical use across different applications.
Dual Perspectives on Fair Evaluation: Developers and Attackers
To evaluate the generative models, it is imperative to address a pivotal yet often overlooked issue: should the evaluation be framed from the standpoint of developers or attackers? From a developer's perspective, evaluations prioritize the model's ethical adherence and its capacity to block harmful interactions entirely, emphasizing moral responsibility and safety. In contrast, attackers assess a model based on its susceptibility to manipulation, where even incorrect or non-responses are deemed failures. Advocating for the developer's perspective in evaluations promotes trustworthiness, focusing on the model's ability to resist exploitation rather than just delivering accurate answers under ideal conditions, thus addressing real-world security challenges.
A Need for Extendable Evaluation in Complex Generative Systems
Current evaluation frameworks are limited in assessing complex generative systems with multiple interacting models and multi-modal outputs. Such systems require advanced evaluation due to (1) dependencies among multiple models, where errors in one model affect others, (2) the need for metrics that assess cross-modality coherence, and (3) challenges in maintaining consistency and scalability as systems grow. Traditional benchmarks fail to capture these dynamics, necessitating new methods that can evaluate inter-model collaboration, multi-modal consistency, and scalability to support the trustworthiness of increasingly intricate generative systems.
Integrated Protection of Model Alignment and External Security
Our work highlight the importance of combining internal alignment mechanisms with external safety protections to enhance the trustworthiness of generative models, particularly large language and vision models. Internal alignment faces limitations, such as inherent flaws in current alignment methods and reduced model utility when safety is overly prioritized. Meanwhile, external protections, like moderators and classifiers, offer additional layers of security by identifying harmful content and adapting to dynamic scenarios without compromising the model's core functionality. This integrated approach promises a safer, more adaptable framework for deploying generative models across diverse applications.
Interdisciplinary Collaboration is Essential to Ensure Trustworthiness
Interdisciplinary collaboration with generative models fosters a mutually beneficial relationship: by integrating insights from fields such as ethics, psychology, and domain-specific expertise, we gain a comprehensive understanding of model trustworthiness, robustness, and reliability. This diverse input not only informs the development of safer and more ethical generative models but also enhances the disciplines involved by enabling trustworthy models to advance research, improve decision-making, and support autonomous systems. This synergy promotes a continuous cycle of innovation, driving progress in both the models themselves and across the broader scientific and technological landscape.
When Generative Models Meets Ethical Dilemma
The integration of generative models in decision-making highlights ethical complexities, as models exhibit varied responses to moral dilemmas. While some models remain neutral, others prioritize utilitarian outcomes or display biases, such as favoring pedestrian safety or emotionally influenced decisions. This diversity reveals the lack of a unified ethical framework, emphasizing the need for interdisciplinary research and transparency tools. Future efforts should focus on aligning models with societal values, especially for applications in sensitive domains like healthcare and law enforcement.
Broad Impacts of Trustworthiness: From Individuals to Society and Beyond
The trustworthiness of generative models has significant individual and societal impacts. On a personal level, these models affect privacy, decision-making, and mental health, with biased outputs perpetuating stereotypes and privacy risks. Societally, they amplify misinformation, economic disruption, and systemic inequality, reinforcing biases and undermining trust in media. Additionally, their high resource demands strain the environment. Ensuring fairness, transparency, and accountability in these models is essential to harness their benefits while minimizing risks.
Alignment: A Double-Edged Sword? Investigating Untrustworthy Behaviors Resulting from Instruction Tuning
A significant distinction of advanced LLMs is their enhanced ability to follow human instructions, achieved through alignment techniques such as PPO and RLHF. While alignment embeds human values to improve helpfulness and safety, it can also lead to unintended issues, including sycophantic responses, deceptive alignment, overoptimization, and power-seeking behaviors. Mechanistic interpretability offers a promising approach to understanding these behaviors by clarifying model inner workings. Future research should aim to refine alignment methods and develop strategies to mitigate these unintended consequences, enhancing the trustworthiness of large models.
Lessons Learned in Ensuring Fairness of Generative Foundation Models
Fairness in generative models is complex and context-dependent, requiring adaptations to different groups' needs rather than a one-size-fits-all approach. True fairness goes beyond equal treatment, fostering cross-group understanding and empowering users with unbiased information rather than dictating choices. Fairness must be assessed in both the model's development and its outputs to ensure equitable results. Social disparities complicate fairness further, as strict equality can perpetuate inequity; thus, nuanced adjustments may be necessary. Additionally, models must handle factual statements carefully to avoid subtle disparagement, presenting data in ways that do not reinforce harmful stereotypes.
Balancing Dynamic Adaptability and Consistent Safety Protocols in LLMs to Eliminate Jailbreak Attacks
To address the vulnerabilities in generative models posed by jailbreak attacks, there is a need for robust safety protocols that ensure consistency across varying inputs. Jailbreaks exploit models' adaptability, using rephrasing and contextual shifts to bypass safety measures. Traditional safety training methods, like fine-tuning or RLHF for safety, focus on specific harmful inputs but are insufficient for handling the vast potential rephrasings that could still produce harmful outputs. A proposed solution is a "multi-level consistency supervision mechanism," which involves training models to generate safe responses for semantically similar queries, regardless of rephrasing, adding a context-sensitive detection module to monitor intent shifts in conversations, and applying post-output defenses to verify adherence to safety protocols in real-time. This comprehensive approach reduces the reliance on input-based safety, strengthens security across diverse contexts, and provides dynamic policy adaptation to maintain safety without compromising the model's utility for various user needs.
The Potential and Peril of LLMs for Application: A Case Study of Cybersecurity
The integration of LLMs into cybersecurity brings both innovation and risk. While frameworks like SWE-bench and Cybench showcase their potential in areas like cryptography and automated testing, LLMs also amplify threats. They can accelerate zero-day exploit discovery, automate advanced social engineering, and generate polymorphic malware that evades detection. Beyond cybersecurity, similar risks arise: LLMs can create synthetic disinformation, fraudulent academic research, and accelerate dual-use technologies in genetic engineering or pharmaceuticals. Current governance efforts, such as OpenAI's Usage Guidelines and Microsoft's AI Framework, remain preliminary. Moving forward, priorities include developing domain-agnostic detection systems, adaptive defense mechanisms leveraging reinforcement learning, and robust red-teaming frameworks to preempt vulnerabilities. The cybersecurity experience highlights the need for comprehensive governance to balance AI's transformative potential with safeguards against misuse.
Trustworthiness of Generative Foundation Models in Medical Domain
Integrating GenFMs into healthcare faces challenges in data quality, explainability, and regulation. Medical data is often noisy, incomplete, and constrained by privacy laws like HIPAA and GDPR, limiting sharing and model generalization. Standardized formats and secure collaborations are needed. Model explainability is vital for clinical trust, as opaque AI systems hinder adoption in high-stakes decisions. Techniques like feature visualization and attention mechanisms aim to enhance transparency without sacrificing performance, enabling collaboration between clinicians and AI. Regulatory frameworks struggle with the dynamic nature of GenFMs. Issues like liability, validation of iterative updates, and accountability require clearer standards. Collaborative efforts among policymakers, developers, and regulators are essential to ensure these models are safe, reliable, and ethically deployed in healthcare.
Trustworthiness of Generative Foundation Models in AI for Science
Generative models in scientific fields like chemistry, biology, and materials science present unique trustworthiness challenges due to the critical need for precision, safety, and ethical compliance. While these models can accelerate discovery, they also risk generating harmful outputs, requiring a balance between innovation and caution. Trust in model outputs relies on transparency, validation, and clear uncertainty measures; human oversight remains essential to assess AI predictions critically. Responsible deployment frameworks, phased testing, ethical constraints, and experimental validation help ensure reliability and safety. This collaborative human-AI approach supports rapid scientific progress while upholding essential standards for safe and ethical application.
Trustworthiness Concerns in Robotics and Other Embodiment of Generative Foundation Models
The integration of large language and vision-language models into robots enhances their processing and recognition abilities but introduces safety risks. LLMs and VLMs can generate hallucinations and misinterpretations, which, when applied to robots, may lead to unsafe actions in the real world. Safety concerns arise in two areas: reasoning and planning, where poor decisions can cause accidents, and physical actions, where incorrect or forceful movements can harm humans or damage objects. Ensuring safety in embodied AGI requires robust control of both cognitive and physical behaviors, with adaptability to unexpected situations.
Trustworthiness of Generative Foundation Models in Human-AI Collaboration
Human-AI collaboration offers transformative potential but raises challenges in trust calibration and accountability. Trust calibration involves balancing overtrust and undertrust in AI outputs. Users' limited understanding of GenFMs, coupled with their opaque nature, complicates this process. Strategies like verbalized confidence scores, uncertainty estimation, and intuitive explainability mechanisms can help users evaluate AI reliability, fostering confident and effective collaboration. Accountability remains a significant concern, especially in error attribution. Determining whether errors stem from AI, humans, or both is complex. Solutions include fine-grained audits, decision pathway logging, and context-aware explanations. Error-aware interfaces that visually trace AI logic and flag issues can promote transparency and critical user engagement. By clarifying responsibility and improving system transparency, trust and accountability are strengthened, ensuring robust, ethical human-AI collaboration in high-stakes applications.
The Role of Natural Noise in Shaping Model Robustness and Security Risks
Robustness is a critical metric for evaluating GenFMs, measuring response consistency under natural perturbations. Our analysis highlights two key considerations: (1) Balancing robustness and overfitting risks. While adversarial training generally improves model stability, excessive optimization can lead to overfitting, reducing generalization to novel perturbations and degrading primary task performance. Balanced approaches are essential to mitigate these risks while leveraging noise benefits. (2) Diftness for prompt types. Models demonstrate higher robustness in close-ended queries, where consistency is crucial for safety-critical applications like autonomous driving or healthcare. Errors in such scenarios can have severe consequences. Open-ended queries, by contrast, tolerate variability, focusing more on coherence and relevance than strict consistency. Addressing these distinct needs ensures robust, reliable performance across both query types, enhancing GenFMs applicability in diverse, high-stakes contexts.
Confronting Advanced AI Risks: A New Paradigm for Governing GenFMs
The rapid evolution of GenFMs introduces Advanced AI Risks, requiring proactive governance beyond traditional mitigation strategies. (1) Self-replication and autonomy: GenFMs capable of autonomous replication or executing cyberattacks and bioengineering tasks pose catastrophic risks, necessitating safeguards to prevent misuse. (2) Persuasion and manipulation: These models can influence emotions and political opinions, threatening societal integrity and democratic processes. (3) Anthropomorphism: Assigning human-like traits to AI inflates trust, obscures accountability, and fosters misplaced confidence. Addressing these risks demands a comprehensive approach: clarifying AI intent and agency, prioritizing human oversight to ensure AI remains subordinate to human decision-making, and recognizing the systemic nature of advanced risks requiring global cooperation. Frameworks like Anthropic's AI Safety Levels (ASL) categorize models based on potential threats, aligning safety measures with risk tiers. Continuous monitoring and dynamic trustworthiness criteria are essential to preempt vulnerabilities as GenFMs advance.
Our Team